You are reading help file online using chmlib.com
|
You are reading help file online using chmlib.com
|

Overview of SAPI 5.0 Architecture
Creating and Initializing the Engine - ISpObjectWithToken
Receiving Calls from SAPI - ISpTTSEngine
Writing Data Back to SAPI - ISpTTSEngineSite
Getting Real-Time Action Requests
Creating an Engine Properties UI - ISpTokenUI
The Microsoft Speech API (SAPI) is a layer of software which sits between applications and speech engines, allowing them to communicate in a standardized way. One of its main goals is enabling application developers to use speech technology in a simple and straightforward way. Another goal is solving some of the more basic complications of developing speech engines, such as audio device manipulation and threading issues, thus allowing engine developers to focus on speech.
From an engine vendor’s point of view, there are a number of technical advantages to using SAPI 5 over SAPI 4:
§ The SAPI 5 DDI has been greatly simplified.
§ SAPI 5 can handle all audio format conversion for the TTS engine.
§ SAPI 5 parses SAPI 5 XML for the TTS engine. Engine proprietary tags are passed to the engine untouched, allowing the engine to interpret them.
§ SAPI 5 performs parameter validation for the engine.
§ SAPI 5 has lexicon management features.
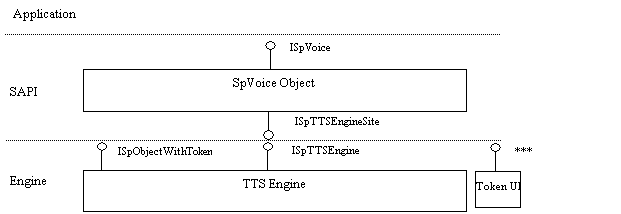
There are two main objects of interest to a TTS Engine developer: the SpVoice object (SAPI) and the TTS Engine object (refer to figure 2). The third object in the figure is a UI component which an engine may or may not implement.
The SpVoice object implements two interfaces which we will be concerned with – ISpVoice, which is the interface which the application uses to access TTS functionality, and ISpTTSEngineSite, which the engine uses to write audio data and queue events. The TTS Engine must implement two interfaces as well – ISpTTSEngine, which is the interface through which SAPI will call the engine, and ISpObjectWithToken, which is the interface through which SAPI will create and initialize the engine. The UI object, if it exists, must implement ISpTokenUI, through which it will be accessed by the SAPI control panel (or, potentially, other applications).
For the most part this document is not concerned with ISpVoice, and so it won’t be covered in any detail. Each of the other interfaces, however, will be discussed in depth.
 |
One important thing to realize about the SAPI 5 architecture is that while SAPI knows about TTS Engines, applications only know about TTS voices. The difference between these two is fairly obvious - one engine implementation can potentially support any number of different voices, with the only differences being data files, parameters, etc. What this means at the engine level is that an engine will be created by one of its voices, in a certain sense.
SAPI 5 uses tokens to represent resources available on a computer (see the Object Tokens and Registry Settings White Paper for more details), including TTS voices. These tokens contain the CLSID of the objects they represent, as well as various attributes of those objects. When an application wishes to use a TTS voice, SAPI will get that voice's token from the registry. Through the voice token, an engine will be cocreated using its CLSID. The SpVoice object then queries the engine for the ISpObjectWithToken interface, through which it calls SetObjectToken.
Here is an example of what a voice token might look like in the registry (voices are located under HKEY_LOCAL_MACHINE\SOFTWARE\MICROSOFT\Speech\Voices\Tokens):
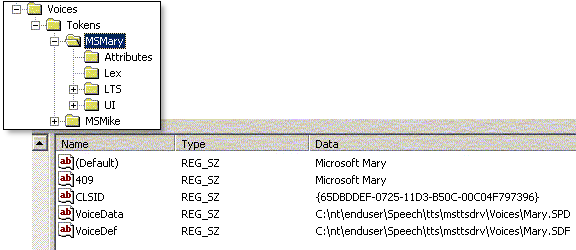

The SetObjectToken call gives the TTS Engine a pointer to the token (and thus the voice) from which it was created, which gives the Engine a chance to initialize itself based on information stored in the token. In the example token above, the VoiceData and VoiceDef keys in the token allow the TTS engine to load the appropriate voice data, once it has a pointer to the token. Similarly, the Lex and LTS subkeys allow the TTS engine to load the appropriate lexicon and letter-to-sound rules.
Again, for more details on registering a TTS engine, see the Object Tokens and Registry Settings White Paper.
Once an engine has been created SAPI will begin calling the engine using ISpTTSEngine. ISpTTSEngine has only two methods – GetOutputFormat and Speak.
GetOutputFormat is used to query the engine about a specific output format – the engine should examine the desired output format and return to the SpVoice object the closest format which it supports. This function may potentially be called many times during the life of the engine.
HRESULT GetOutputFormat(
[in] const GUID * pTargetFmtId,
[in] const WAVEFORMATEX * pTargetWaveFormatEx,
[out] GUID * pOutputFormatId,
[out] WAVEFORMATEX ** ppCoMemOutputWaveFormatEx
);
In the normal case, pTargetFmtId will be SPDFID_WaveFormatEx, and pTargetWaveFormatEx will be a pointer to a WAVEFORMATEX structure describing the desired output format. In this case, the engine should set pOutputFormatId to SPDFID_WaveFormatEx, allocate space (using ppCoMemOutputWaveFormatEx) for a WAVEFORMATEX structure, and set it to the closest format to pTargetWaveFormatEx it supports.
If pTargetFmtId is NULL, the engine should simply return to SAPI its default format.
NOTE: If pTargetFmtId is SPDFID_Text, engines can do whatever they please. Essentially, this format type if provided for debugging purposes – it is not required that any engine support this for SAPI 5.0 compliance, nor is it required that engines to do anything specific with this format if they do support it.
See the Sample TTS Engine's GetOutputFormat implementation for more details.
Speak is the main function of the interface – it passes the engine the text to be rendered, an output format to render it in, and an output site to which the engine should write audio data and events. A Speak call should return when either all of the input text has been rendered, or the engine has been told to abort the call by the SpVoice object. Let’s look at the parameters in more detail.
HRESULT Speak(
[in]DWORD
dwSpeakFlags,
[in]REFGUID rguidFormatId,
[in]const WAVEFORMATEX * pWaveFormatEx,
[in]const
SPVTEXTFRAG* pTextFragList,
[in]ISpTTSEngineSite* pOutputSite,
);
The first parameter of the Speak call, dwSpeakFlags, is a DWORD which will have one of two values – 0, or SPF_NLP_SPEAK_PUNC (all other flags in the SPEAKFLAGS enumeration are masked out, since they are handled by SAPI). If the value is SPF_NLP_SPEAK_PUNC, the engine should speak all punctuation (e.g. “This is a sentence.” should be expanded to “This is a sentence period”).
The second and third parameters of the Speak call will specify the output format which the engine should use for rendering the text passed in for this call. This format is guaranteed to be one which the engine told SAPI it supports using a previous GetOutputFormat call. Again, if this rguidFormatId is SPDFID_Text, it is not required that engines support this format, nor is it required that engines do anything specific with this format if it is supported.
The fourth parameter is the text to be rendered in the form of a linked list of SPVTEXTFRAGs. Let’s look at this structure in more detail.
typedef struct SPVTEXTFRAG
{
struct SPVTEXTFRAG *pNext;
SPVSTATE State;
LPCWSTR pTextStart;
ULONG ulTextLen;
ULONG ulTextSrcOffset;
} SPVTEXTFRAG;
pTextStart is a pointer to the beginning of the text associated with the fragment. ulTextLen is the length of this text, in WCHARs. ulTextSrcOffset is the offset of the first character of the text associated with the fragment. Finally, State is the SAPI 5.0 XML state associated with this fragment (see the XML Schema : SAPI white paper for more details on SAPI 5 XML markup).
typedef [restricted] struct SPVSTATE
{
SPVACTIONS eAction;
LANGID LangID;
WORD wReserved;
long EmphAdj;
long RateAdj;
ULONG Volume;
SPVPITCH PitchAdj;
ULONG SilenceMSecs;
SPPHONEID *pPhoneIds;
SPPARTOFSPEECH ePartOfSpeech;
SPVCONTEXT Context;
} SPVSTATE;
eActions is an enumerated value which tells the engine what it should do with this fragment.
typedef enum SPVACTIONS
{
SPVA_Speak = 0,
SPVA_Silence,
SPVA_Pronounce,
SPVA_Bookmark,
SPVA_SpellOut,
SPVA_Section,
SPVA_ParseUnknownTag
} SPVACTIONS;
SPVA_Speak (the default value) means that the engine should process the text associated with the fragment and render it in the proper output format. SPVA_Silence means that SAPI was passed a <Silence> SAPI 5.0 XML tag, and that the engine should write SilenceMSecs (see structure SPVSTATE) milliseconds of silence. SPVA_Pronounce means that SAPI was passed a <Pron> SAPI 5.0 XML tag, and that the engine should use pPhoneIds (see structure SPVSTATE) as the pronunciation of the associated text, or just insert the pronunciation if there is no associated text. SPVA_Bookmark means that SAPI was passed a <Bookmark> SAPI 5.0 XML tag, and that the engine should write a Bookmark event (see below for information on writing events). SPVA_SpellOut means that the engine should spell out the associated text letter by letter, including punctuation and miscellaneous characters (and render this expanded version of the text in the proper output format). SPVA_Section is currently unused. SPVA_ParseUnknownTag means that a non-SAPI 5.0 XML tag was passed to SAPI – if the engine supports additional tags, it should attempt to parse this tag. Otherwise, it should just ignore it.
LANGID will be zero, unless a language was specified to SAPI using a <Lang> SAPI 5.0 XML tag.
EmphAdj will be zero, unless SAPI was passed an <Emph> SAPI 5.0 XML tag.
RateAdj will be 0, unless SAPI was passed a <Rate> SAPI 5.0 XML tag. This gives the absolute rate which the engine should use to render the text associated with this fragment. NOTE:
the engine should combine these values with values obtained through ISpTTSEngineSite::GetRate calls to arrive at a final value.
Volume will be 100, unless SAPI was passed a <Volume> SAPI 5.0 XML tag. This gives the absolute volume which the engine should use to render the text associated with this fragment. NOTE: the engine should combine these values with values obtained through ISpTTSEngineSite::GetVolume calls to arrive at a final value.
PitchAdj will have a MiddleAdj of zero and a RangeAdj of zero, unless SAPI was passed a <Pitch> SAPI 5.0 XML tag. This gives the absolute pitch middle and range which the engine should use to render the text associated with this fragment (the pitch middle is used to raise or lower the overall pitch of the voice, the pitch range is used to expand or contract the pitch range of the voice, making it more or less monotone).
typedef struct SPVPITCH
{
long MiddleAdj;
long RangeAdj;
} SPVPITCH;
ePartOfSpeech will be SPPS_Unknown (see SPPARTOFSPEECH) unless SAPI was passed a <PartOfSp> SAPI 5.0 XML tag. This part of speech should be used for the text associated with this fragment (e.g. to disambiguate a word with multiple pronunciations).
Finally, the pointers within Context will be NULL unless SAPI was passed a <Context> SAPI 5.0 XML tag.
typedef [restricted] struct SPVCONTEXT
{
LPCWSTR pCategory;
LPCWSTR pBefore;
LPCWSTR pAfter;
} SPVCONTEXT;
This field can be used to disambiguate items in the text associated with this fragment (e.g. ambiguous date formats).
Let’s look at an example of a fragment list.
Imagine this text is passed to SAPI:
"This is a
<PITCH MIDDLE = '6'> sample piece of <PARTOFSP PART = 'Noun'> text
</PARTOFSP> which will <BOOKMARK MARK = '1'/> demonstrate <VOLUME
LEVEL = '30'> what a <VOLUME LEVEL = '90'> fragment </VOLUME>
list </VOLUME> looks like </PITCH> conceptually."
This will be the resulting linked list of SPVTEXTFRAGs passed to the TTS Engine:
SPVTEXTFRAGs
|
Element 1
|
Element 2
|
||
|
pNext
|
Element 2
|
Element 3
|
||
|
State
|
eAction
|
SPVA_Speak
|
SPVA_Speak
|
|
|
LangId
|
0
|
0
|
||
|
EmphAdj
|
0
|
0
|
||
|
RateAdj
|
0
|
0
|
||
|
Volume
|
100
|
100
|
||
|
PitchAdj
|
MiddleAdj
|
0
|
6
|
|
|
RangeAdj
|
0
|
0
|
||
|
SilenceMSecs
|
0
|
0
|
||
|
pPhoneIds
|
NULL
|
NULL
|
||
|
ePartOfSpeech
|
SPPS_Unknown
|
SPPS_Unknown
|
||
|
Context
|
pCategory
|
NULL
|
NULL
|
|
|
pBefore
|
NULL
|
NULL
|
||
|
pAfter
|
NULL
|
NULL
|
||
|
pTextStart
|
“This is a <PITCH …“
|
“sample piece of <PART…”
|
||
|
ulTextLen
|
10
|
16
|
||
|
ulTextSrcOffset
|
0
|
31
|
||
SPVTEXTFRAGs
|
Element 3
|
Element 4
|
Element 5
|
||
|
pNext
|
Element 4
|
Element 5
|
Element 6
|
||
|
State
|
eAction
|
SPVA_Speak
|
SPVA_Speak
|
SPVA_Bookmark
|
|
|
LangId
|
0
|
0
|
0
|
||
|
EmphAdj
|
0
|
0
|
0
|
||
|
RateAdj
|
0
|
0
|
0
|
||
|
Volume
|
100
|
100
|
100
|
||
|
PitchAdj
|
MiddleAdj
|
6
|
6
|
6
|
|
|
RangeAdj
|
0
|
0
|
0
|
||
|
SilenceMSecs
|
0
|
0
|
0
|
||
|
pPhoneIds
|
NULL
|
NULL
|
NULL
|
||
|
ePartOfSpeech
|
SPPS_Noun
|
SPPS_Unknown
|
SPPS_Unknown
|
||
|
Context
|
pCategory
|
NULL
|
NULL
|
NULL
|
|
|
pBefore
|
NULL
|
NULL
|
NULL
|
||
|
pAfter
|
NULL
|
NULL
|
NULL
|
||
|
pTextStart
|
“text </PART…”
|
“which will <B…”
|
“1’/> demonstrate…”
|
||
|
ulTextLen
|
5
|
11
|
1
|
||
|
ulTextSrcOffset
|
72
|
89
|
100
|
||
SPVTEXTFRAGs
|
Element 6
|
Element 7
|
Element 8
|
||
|
pNext
|
Element 7
|
Element 8
|
Element 9
|
||
|
State
|
eAction
|
SPVA_Speak
|
SPVA_Speak
|
SPVA_Speak
|
|
|
LangId
|
0
|
0
|
0
|
||
|
EmphAdj
|
0
|
0
|
0
|
||
|
RateAdj
|
0
|
0
|
0
|
||
|
Volume
|
100
|
30
|
90
|
||
|
PitchAdj
|
MiddleAdj
|
6
|
6
|
6
|
|
|
RangeAdj
|
0
|
0
|
0
|
||
|
SilenceMSecs
|
0
|
0
|
0
|
||
|
pPhoneIds
|
NULL
|
NULL
|
NULL
|
||
|
ePartOfSpeech
|
SPPS_Unknown
|
SPPS_Unknown
|
SPPS_Unknown
|
||
|
Context
|
pCategory
|
NULL
|
NULL
|
NULL
|
|
|
pBefore
|
NULL
|
NULL
|
NULL
|
||
|
pAfter
|
NULL
|
NULL
|
NULL
|
||
|
pTextStart
|
“demonstrate <V…”
|
“what a <VOL…”
|
“fragment </VOL…”
|
||
|
ulTextLen
|
12
|
7
|
9
|
||
|
ulTextSrcOffset
|
123
|
157
|
186
|
||
SPVTEXTFRAGs
|
Element 9
|
Element 10
|
Element 11
|
||
|
pNext
|
Element 10
|
Element 11
|
Element 12
|
||
|
State
|
eAction
|
SPVA_Speak
|
SPVA_Speak
|
SPVA_Speak
|
|
|
LangId
|
0
|
0
|
0
|
||
|
EmphAdj
|
0
|
0
|
0
|
||
|
RateAdj
|
0
|
0
|
0
|
||
|
Volume
|
30
|
100
|
100
|
||
|
PitchAdj
|
MiddleAdj
|
6
|
6
|
0
|
|
|
RangeAdj
|
0
|
0
|
0
|
||
|
SilenceMSecs
|
0
|
0
|
0
|
||
|
pPhoneIds
|
NULL
|
NULL
|
NULL
|
||
|
ePartOfSpeech
|
SPPS_Unknown
|
SPPS_Unknown
|
SPPS_Unknown
|
||
|
Context
|
pCategory
|
NULL
|
NULL
|
NULL
|
|
|
pBefore
|
NULL
|
NULL
|
NULL
|
||
|
pAfter
|
NULL
|
NULL
|
NULL
|
||
|
pTextStart
|
“list </VOL…”
|
“looks like </PIT…”
|
“conceptually.”
|
||
|
ulTextLen
|
5
|
11
|
14
|
||
|
ulTextSrcOffset
|
205
|
220
|
240
|
||
The last parameter of the Speak call is an ISpTTSEngineSite pointer – pOutputSite. This pointer should be stored by the engine, as it will be used to write audio data and events back to the SpVoice object, as well as to poll the SpVoice object for real-time action requests.
Within a Speak call, an Engine should call ISpTTSEngineSite::GetActions as often as possible to ensure near real-time processing of SAPI actions. This is an inexpensive call – it simply returns a DWORD which will contain one or more values from the SPVESACTIONS enumeration.
DWORD GetActions( void );
typedef enum SPVESACTIONS
{
SPVES_CONTINUE = 0,
SPVES_ABORT = ( 1L << 0 ),
SPVES_SKIP = ( 1L << 1 ),
SPVES_RATE = ( 1L << 2 ),
SPVES_VOLUME = ( 1L << 3 )
} SPVESACTIONS;
SPVES_CONTINUE is the default case (no actions) – it means to continue processing normally. SPVES_ABORT means that the engine should abort the Speak call and return immediately. The other three cases require a bit more explanation.
SPVES_VOLUME – the engine should call ISpTTSEngineSite::GetVolume, which will return a new volume level. The engine should adjust its volume level accordingly. Note that when no XML volume has been specified, the level returned by GetVolume should be exactly the level used by the engine, but if the volume is already affected by an XML tag, the final volume should be a combination of the two.
HRESULT GetVolume(
[out] USHORT *pusVolume
);
SPVES_RATE – the engine should call ISpTTSEngineSite::GetRate, which will return a new rate level. The engine should adjust its rate level accordingly. Note that, similarly to volume, XML rate levels and GetRate rate levels should be combined to produce the final rate.
HRESULT GetRate(
[out] long *pRateAdjust
);
SPVES_SKIP – the engine should call ISpTTSEngineSite::GetSkipInfo, which will return a type of unit to skip (currently only sentences are supported) and the number of such units to skip. This number can be positive (skip forward in the text), negative (skip backward in the text), or zero (skip to the beginning of the current item). The engine should stop writing data to SAPI, skip the appropriate number of units (or as many as it can) and then call ISpTTSEngineSite::CompleteSkip to tell SAPI how many units it was able to successfully skip. If it was able to successfully skip the entire number returned by GetSkipInfo, the engine should then continue rendering text at the appropriate point. Otherwise, it should abort the current Speak call and return immediately.
HRESULT GetSkipInfo(
[out] SPVSKIPTYPE *peType,
[out] long *plNumItems
);
HRESULT CompleteSkip(
[in] long ulNumSkipped
);
As an example, imagine an engine was passed this text:
“This is sentence one. This is sentence two. This is sentence three.”
Now suppose that the engine was currently rendering the second sentence when it discovered, using GetActions and GetSkipInfo, that it was being asked to skip +1 sentence. The engine should stop rendering the second sentence, skip forward to the third sentence, call CompleteSkip with a parameter of +1, and begin rendering the third sentence. Now imagine that the engine was asked to skip –2 sentences. The engine should again stop rendering the second sentence, and then skip backward until it discovers that it cannot skip the appropriate number. It would then call CompleteSkip with a parameter of –1 and abort its Speak call.
Events are structures which are used to pass information from the engine back to the application. The engine is responsible for generating certain types of events, and then handing them to SAPI through the function ISpTTSEngineSite::AddEvents. SAPI will then take care of firing the events at the appropriate times.
HRESULT AddEvents(
[in] const SPEVENT* pEventArray,
[in] ULONG ulCount
);
Engines should call the function ISpTTSEngineSite::GetEventInterest, which will tell them which events the application (and/or SAPI) is interested in receiving.
HRESULT GetEventInterest(
[out] ULONGLONG * pullEventInterest
);
This function will return (using pullEventInterest) a ULONGLONG which will contain one or more values from the TTS subset of the SPEVENTENUM enumeration:
§ SPEI_TTS_BOOKMARK
§ SPEI_WORD_BOUNDARY
§ SPEI_SENTENCE_BOUNDARY
§ SPEI_PHONEME
§ SPEI_VISEME
The engine must then generate the appropriate types of events. Here is the structure of an SPEVENT:
typedef [restricted] struct SPEVENT
{
WORD eEventId;
WORD elParamType;
ULONG ulStreamNum;
ULONGLONG ullAudioStreamOffset;
WPARAM wParam;
LPARAM lParam;
} SPEVENT;
Note that SAPI is responsible for setting ulStreamNum – the engine need not worry about this field. ullAudioStreamOffset should in each case be the byte (not sample) offset in the audio stream at which the event should be fired. NOTE: this offset should correspond to a sample boundary.
Let’s go through what the various fields of the SPEVENT structure correspond to for each event type.
The SPEI_TTS_BOOKMARK event indicates that the TTS engine has reached a bookmark. Here is the format for the fields of the Bookmark event:
|
SPEVENT Field
|
Bookmark event
|
|
eEventId
|
SPEI_TTS_BOOKMARK
|
|
elParamType
|
SPET_LPARAM_IS_STRING
|
|
wParam
|
Value of the bookmark string when converted to a long (_wtol(...) can be used) |
|
lParam
|
Null terminated copy of the bookmark string
|
For example, if an engine
was passed a bookmark corresponding to this XML marked up text:
“<BOOKMARK MARK=”this is a bookmark”/>”
The engine would need to generate an event whose lParam was “this is a bookmark”. If the engine was passed a bookmark corresponding to this XML marked up text:
“<BOOKMARK MARK='1'/>”
The engine would need to generate an event whose wParam was equal to the integer, one.
The SPEI_WORD_BOUNDARY event indicates that the TTS engine has started synthesizing a word. Here is the format for the fields of the word boundary event:
|
SPEVENT Field
|
Word Boundary event
|
|
eEventId
|
SPEI_WORD_BOUNDARY
|
|
elParamType
|
SPET_LPARAM_IS_UNKNOWN
|
|
wParam
|
Character offset of the beginning of the word being synthesized. |
|
lParam
|
Character length of the word in the current input stream being synthesized
|
The SPEI_SENTENCE_BOUNDARY event indicates that the TTS engine has started synthesizing a sentence. Here is the format for the fields of the sentence boundary event:
|
SPEVENT Field
|
Sentence Boundary event
|
|
eEventId
|
SPEI_SENTENCE_BOUNDARY
|
|
elParamType
|
SPET_LPARAM_IS_UNKNOWN
|
|
wParam
|
Character offset of the beginning of the sentence being synthesized. |
|
lParam
|
Character length of the sentence in the current input stream being synthesized
|
The SPEI_PHONEME event indicates that the TTS engine has synthesized a phoneme. Here is the format for the fields of the phoneme event:
|
SPEVENT Field
|
Phoneme event
|
|
eEventId
|
SPEI_PHONEME
|
|
elParamType
|
SPET_LPARAM_IS_UNKNOWN
|
|
wParam
|
The high word is the duration in milliseconds of the current phoneme. The low word is the PhoneID of the next phoneme.
|
|
lParam
|
The low word is the PhoneID of the current phoneme. The high word is the SPVFEATURE value associated with the current phoneme.
|
See Appendix A for the SAPI 5.0 phoneme set.
SPVFEATURE contains two flags – SPVFEATURE_STRESSED, which means that the phoneme is stressed relative to the other phonemes of a word (stress is usually associated with the vowel of a stressed syllable), while SPVFEATURE_EMPHASIS means that the phoneme is part of an emphasized word. That is, stress is a syllabic phenomenon within a word, while emphasis is a word-level phenomenon within a sentence.
The SPEI_VISEME event indicates that the TTS engine has synthesized a viseme. Here is the format for the fields of the viseme event:
|
SPEVENT Field
|
Viseme event
|
|
eEventId
|
SPEI_VISEME
|
|
elParamType
|
SPET_LPARAM_IS_UNKNOWN
|
|
wParam
|
The high word is the duration in milliseconds of the current viseme. The low word is the code for the next viseme
|
|
lParam
|
The low word is the code of the current viseme. The high word is the SPVFEATURE value associated with the current viseme (and phoneme).
|
The SAPI visemes are based off the Disney 13 Visemes and are described in Appendix B for the SAPI American English phoneme set.
After an engine has queued events, it should write audio data to the output site in the appropriate format. NOTE: the order of these two events is important – events should not be queued after their associated audio data has already been written or they cannot be fired at the proper times. The function ISpTTSEngineSite::Write is used to write audio data.
HRESULT Write(
const void* pBuff,
ULONG cb,
ULONG *pcbWritten
);
This function is straightforward – pBuff points to a buffer of audio data to be written to the output site, cb is the number of bytes (not samples) to be written, and pcbWritten will return the number of bytes actually written (which should be the same as cb, assuming nothing has gone wrong). NOTE: only complete samples should be written. If the Write function returns SP_AUDIO_STOPPED the audio device has been stopped and the Speak call should abort immediately.
It should be noted that if an engine (from the application's perspective, a voice) is paused (using ISpVoice::Pause), SAPI will block an ISpTTSEngineSite::Write call until the engine is to resume. The same thing will happen if an alert priority voice interrupts a normal priority voice (see ISpVoice::SetPriority for more information on voice priorities).
TTS Engines may wish to supply various UI components - one example is an Engine Properties component which users can access through the SAPI 5.0 control panel. SAPI provides mechanisms for engines to describe what UI components they have, and for applications to request the display of these components.
The UI components that an engine supports should be contained within the engine voice's object tokens (refer to the Object Tokens and Registry Settings White Paper for more discussion of tokens) within a UI subkey. Within this key should be subkeys for each UI component the engine implements. For example, an engine properties component would be in HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\{Voice Name}\UI\EngineProperties. The EngineProperties key would then contain the CLSID of the class to be created when this UI component is displayed. The engine setup should install and register this class, and the class must implement the interface ISpTokenUI.
An application can then see if a particular UI component is supported by an engine by calling ISpTokenUI::IsSupportedUI on the engine's object token.
[local] HRESULT IsUISupported(
[in] const WCHAR *pszTypeOfUI,
[in] void *pvExtraData,
[in] ULONG cbExtraData,
[in] IUnknown *punkObject,
[out] BOOL *pfSupported
);
Here is an example implementation of IsUISupported:
STDMETHODIMP EnginePropertiesUI::IsUISupported(
const WCHAR* pszTypeOfUI,
void * /*pvExtraData*/,
ULONG /*cbExtraData*/,
IUnknown * /*punkObject*/,
BOOL *pfSupported )
{
*pfSupported = false;
if ( wcscmp( pszTypeOfUI, SPDUI_EngineProperties ) == 0 )
{
*pfSupported = true;
}
return S_OK;
}
SPDUI_EngineProperties is just the string, "EngineProperties" - this is the string which the SAPI 5.0 control panel uses to query engines for UI components to be displayed when the user clicks the "Settings" button. If this function call returns true (using pfSupported), the application can then call ISpTokenUI::DisplayUI to display the UI component.
[local] HRESULT DisplayUI(
[in] HWND hwndParent,
[in] const WCHAR * pszTitle,
[in] const WCHAR * pszTypeOfUI,
[in] void * pvExtraData,
[in] ULONG cbExtraData,
[in] ISpObjectToken * pToken,
[in] IUnknown * punkObject
);
Here is an example implementation of DisplayUI:
STDMETHODIMP SpTtsEngUI::DisplayUI(
HWND hwndParent,
const WCHAR * pszTitle,
const WCHAR * pszTypeOfUI,
void * /* pvExtraData */,
ULONG /* cbExtraData */,
ISpObjectToken * pToken,
IUnknown * /* punkObject */)
{
HRESULT hr = S_OK;
if ( SUCCEEDED( hr ) )
{
if ( wcscmp( pszTypeOfUI, SPDUI_EngineProperties ) == 0)
{
EnginePropertiesDialog
dlg;
dlg.hInstance = g_hInstance;
dlg.hwndParent = hwndParent;
hr = dlg.Run();
}
}
return hr;
}
SAPI provides lexicons so that users and applications may specify pronunciation and part of speech information for words important to them. As such, all SAPI compliant TTS engines should use these lexicons to guarantee uniformity of pronunciation and part of speech information.
There are two types of lexicons in SAPI:
§ User Lexicons: Each user who logs onto a computer will have a User Lexicon. These are initially empty, but can have words added to them either programmatically, or using an engine's add/remove words UI component (for example, the sample application Dictation Pad provides an Add/Remove Words dialog).
§ Application Lexicons: Applications can create and ship their own lexicons of specialized words - these are read only.
Each of these lexicon types implements the ISpLexicon interface and can be created directly, but SAPI provides a Container Lexicon class which combines the user lexicon and all application lexicons into a single entity, making manipulating the lexicon information much simpler. Here is an example of how to create a Container Lexicon (which will contain the user lexicon and all the application lexicons):
CComPtr<ISpContainerLexicon> cpContainerLexicon;
cpContainerLexicon.CoCreateInstance( CLSID_SpLexicon );
The main lexicon function engines will want to use is ISpLexicon::GetPronunciations:
HRESULT GetPronunciations(
[in] const WCHAR *pszWord,
[in] LANGID LangId,
[in] DWORD dwFlags,
[out][in] SPWORDPRONUNCIATIONLIST *pWordPronunciationList
);
Here is an example of how to get pronunciations out of a Container Lexicon:
HRESULT hr = S_OK;
DWORD dwLexFlags = eLEXTYPE_USER | eLEXTYPE_APP;
SPWORDPRONUNCIATIONLIST SPList;
ZeroMemory( &SPList, sizeof( SPWORDPRONUNCIATIONLIST ) );
hr = cpContainerLexicon->GetPronunciations( pszWord, 1033, dwLexFlags, &SPList );
if ( SUCCEEDED( hr ) )
{
for ( SPWORDPRONUNCIATION *pWordPron = SPList.pFirstWordPronunciation; pWordPron;
pWordPron = pWordPron->pNextWordPronunciation )
{
//--- Do something with each pronunciation
}
}
if ( SPList.pvBuffer )
{
::CoTaskMemFree( SPList.pvBuffer );
}
SPWORDPRONUNCIATIONLIST is the structure SAPI uses to return a list of pronunciations for a word:
typedef struct SPWORDPRONUNCIATIONLIST
{
ULONG ulSize;
BYTE *pvBuffer;
SPWORDPRONUNCIATION *pFirstWordPronunciation;
} SPWORDPRONUNCIATIONLIST;
This structure should be initialized to zeroes before GetPronunciations is called (see the ZeroMemory call in the sample code, above). Furthermore, the memory allocated for the pronunciations which are returned in this structure must be freed by the engine after GetPronunciations is called - this memory is all pointed to by pvBuffer, hence a single ::CoTaskMemFree call will free all of the allocated memory (see the sample code, above). SPWORDPRONUNCIATIONLIST is just a linked list of SPWORDPRONUNCIATIONs:
typedef [restricted] struct SPWORDPRONUNCIATION
{
struct SPWORDPRONUNCIATION *pNextWordPronunciation;
SPLEXICONTYPE eLexiconType;
LANGID LangID;
WORD wReserved;
SPPARTOFSPEECH ePartOfSpeech;
SPPHONEID szPronunciation[1];
} SPWORDPRONUNCIATION;
eLexiconType indicates which type of lexicon this pronunciation came from - in the above sample code, eLexiconType will be either eLEXTYPE_USER or eLEXTYPE_APP for each returned SPWORDPRONUNICATION. szPronunciation is a NULL-terminated array of SPPHONEIDs which runs of the end of the SPWORDPRONUNCIATION structure into the pvBuffer member of SPWORDPRONUNCIATIONLIST;
If a word has a pronunciation in the User Lexicon, that pronunciation should take precedence over pronunciations in engine internal lexicons and pronunciations in Application Lexicons. Application Lexicon pronunciations should similarly take precedence over pronunciations in engine internal lexicons.
For more information on SAPI Lexicons, including adding and removing words from the User Lexicon, or using the basic SAPI Lexicon classes (SpCompressedLexicon, SpUncompressedLexicon) for an engines internal lexicons, see the Lexicon Manager section).
|
SYM |
Example |
PhoneID |
|
- |
syllable boundary (hyphen) |
1 |
|
! |
Sentence terminator (exclamation mark) |
2 |
|
& |
word boundary |
3 |
|
, |
Sentence terminator (comma) |
4 |
|
. |
Sentence terminator (period) |
5 |
|
? |
Sentence terminator (question mark) |
6 |
|
_ |
Silence (underscore) |
7 |
|
1 |
primary stress |
8 |
|
2 |
secondary stress |
9 |
|
aa |
father |
10 |
|
ae |
cat |
11 |
|
ah |
cut |
12 |
|
ao |
dog |
13 |
|
aw |
foul |
14 |
|
ax |
ago |
15 |
|
ay |
bite |
16 |
|
b |
big |
17 |
|
ch |
chin |
18 |
|
d |
dig |
19 |
|
dh |
then |
20 |
|
eh |
pet |
21 |
|
er |
fur |
22 |
|
ey |
ate |
23 |
|
f |
fork |
24 |
|
g |
gut |
25 |
|
h |
help |
26 |
|
ih |
fill |
27 |
|
iy |
feel |
28 |
|
jh |
joy |
29 |
|
k |
cut |
30 |
|
l |
lid |
31 |
|
m |
mat |
32 |
|
n |
no |
33 |
|
ng |
sing |
34 |
|
ow |
go |
35 |
|
oy |
toy |
36 |
|
p |
put |
37 |
|
r |
red |
38 |
|
s |
sit |
39 |
|
sh |
she |
40 |
|
t |
talk |
41 |
|
th |
thin |
42 |
|
uh |
book |
43 |
|
uw |
too |
44 |
|
v |
vat |
45 |
|
w |
with |
46 |
|
y |
yard |
47 |
|
z |
zap |
48 |
|
zh |
pleasure |
49 |
|
VISEME |
Described SAPI Phonemes |
|
SP_VISEME_0 |
Silence |
|
SP_VISEME_1 |
ae, ax, ah |
|
SP_VISEME_2 |
aa |
|
SP_VISEME_3 |
ao |
|
SP_VISEME_4 |
ey, eh, uh |
|
SP_VISEME_5 |
er |
|
SP_VISEME_6 |
y, iy, ih, ix |
|
SP_VISEME_7 |
w, uw |
|
SP_VISEME_8 |
ow |
|
SP_VISEME_9 |
aw |
|
SP_VISEME_10 |
oy |
|
SP_VISEME_11 |
ay |
|
SP_VISEME_12 |
h |
|
SP_VISEME_13 |
r |
|
SP_VISEME_14 |
l |
|
SP_VISEME_15 |
s, z |
|
SP_VISEME_16 |
sh, ch, jh, zh |
|
SP_VISEME_17 |
th, dh |
|
SP_VISEME_18 |
f, v |
|
SP_VISEME_19 |
d, t, n |
|
SP_VISEME_20 |
k, g, ng |
|
SP_VISEME_21 |
p, b, m |
You are reading help file online using chmlib.com
|